Data Preprocessing
Before we can configure and train our model, we need to appropriately preprocess the data to be ready for being inputted into our model. Since images in our dataset are characterized by having a lot of background that is not really relevant to our task of lip-reading, an appropriate preprocessing step was to crop out such unnecessary regions. This saves our model meaningless computations that it would otherwise have to carry out.
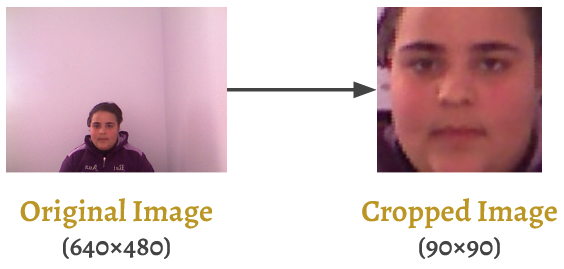
Following [1] and [2], we used OpenCV's face detection module [3] which gave us back the coordinates of a bounding box of the face in each image. We then accordingly cropped the images restricting the size to 90x90 pixels for the sake of consistency across all images.
The following figure shows an example image before and after cropping.
Data Augmentation
Since our dataset contains only 3,000 instances, we perform data augmentation in order to artificially increase the size of our data. We tripled the size of our dataset by carrying out the following two modifications on each image, following [1]:
- Instead of cropping the original image only once using the exact coordinates of the face bounding box, we crop it twice. For the second crop, we slightly shift the bounding box (the crop region) by a random number of pixels horizontally and vertically.
- After the original image is cropped, we create a new intensity-jittered instance of it. We randomly increase or decrease the pixel values of the cropped image by a small amount.
The following GIF shows an example of an original image and the three versions resulting from it.
